
An obvious observation: open-source software has been an integral part of software development for decades. This collaborative approach enables developers across the world to work together on projects in a decentralized manner. Making source code freely available for anyone to inspect, modify, and distribute, allowing for collaborative development and innovation, has produced ubiquitous software used every day.
A further obvious observation: modern Internet technologies have been enabled by open-source development stacks including LAMP, Django, Jamstack, Ruby on Rails, Drupal, and MEAN. By combining these freely available open-source components, developers have been empowered to create dynamic websites, applications, and services without needing to seek formal permissions. With the flexibility, low-cost basis, and community support, open source rules everything around us.
As a venture firm, we ask ourselves, what’s the analogy here with respect to the development of an equivalent AI stack? Is thinking about a stack the right question?
Starting from the infrastructure layer, open-source AI frameworks like PyTorch and TensorFlow allow anyone to build deep learning models with detailed documentation and pre-trained models. Then there is Together AI, decentralized cloud service APIs to AI models.

The application layer is no less interesting: open medical imaging databases to train models to improve diagnostics; educational tools like text-to-speech and speech recognition; and open datasets and models power research advancing science and human knowledge (Clarifai community and Hugging Face to name just two).
How about a different and potentially profound approach: frameworks like Open Interpreter, which lets language models run code on your computer?
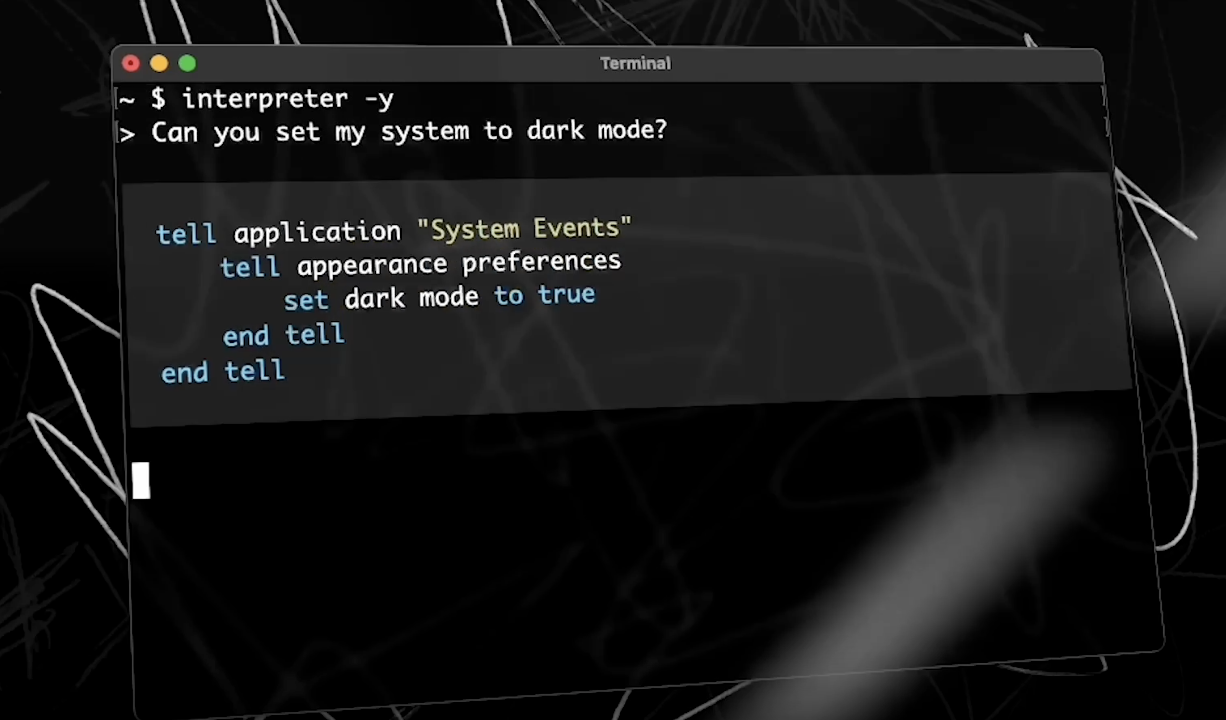
On a more fundamental level, given that most large language models (like GPT-3) were created using immense quantities of text and data from open sources, democratizing access to AI capabilities allows more players to push the capabilities of AI forward.
It’s still unclear precisely how to measure AI’s effect on human well-being. As a result, maybe open-source models will contribute to AI risk. We are encouraged that Hume AI has built an AI toolkit to understand emotional expression and align technology with human well-being. And that smaller open-source models themselves both may not pose much risk and help fuel safety research.
What are some of the other issues? The first is cost. Currently, any model, including open source, requires significant expenses to train the model. This is an important consideration as the closed, proprietary models are increasing their capabilities rapidly – how will the open-source approaches compete at this level? Given the open and decentralized nature of blockchain-based protocols, there may also be a way to use those protocols to incentivize the development and operation of robust open-source AI models. Second: defensibility. If the costs are prohibitive, and the functionality from closed-source seemingly advancing by leaps and bounds almost weekly, how can open-source be defensible as an approach?
Michael Dempsey, of Compound, posits that perhaps the advantage of open-source in the AI world will come from narrative:
The durability of revenue won’t come from continual incremental improvement, but instead from enduring narratives that are able to stand the tests of technological time and the deaths by a thousand cuts via an overcrowded ecosystem.
This is a theme USV has invested against for almost two decades: the notion of permissionless innovation as a driver toward broadening access to capital, learning and well-being.
As Brad opined in writing about our investment in Protocol Labs:
As most of you know all of us at Union Square Ventures believe in the decentralized, emergent, permissionless innovation that was so central to the vitality of the early Internet. Prior to the Internet, the media industry was dominated by a small number of companies that controlled access to in their respective mediums, print, television, radio, cable etc. It was the broad adoption of a set of open protocols, like TCP/IP, SMTP and HTTP, that allowed any creator on the planet to get to any consumer and unleashed the wave of innovation that led to the consumer Internet we know today.
Similarly, Fred wrote back in 2011 that:
For something like seventeen years, I have been investing in entrepreneurs who have had the freedom to innovate on the Internet. It has been a powerful life lesson for me. These people imagine something, they create it, and they are off and running building a business, hiring employees, generating cash flow. They ask nobody for permission. They don’t need any permits. They don’t need any real estate. All they need is a server (now rented in the cloud from Amazon and others) and a laptop or two and they are good to go.
And version 2.0 from 2015 of our investment thesis specifies that:
Since USV was founded, we have focused on the applications layer of the internet. The layer that sits on top of the relatively open and robust infrastructure of the internet, the infrastructure that allows for permissionless connectivity.
There is a saying that history repeats in rhymes, not verbatim. If so, the stanza we keep coming back to, particularly now, is what is it about permissionless innovation, experimentation and creativity that leads to the “emergent innovation we have all come to expect on the Internet.” (Brad, writing in 2013). Where will we find opaque ideas shaped by open collaboration? Distributed progress arising from decentralized knowledge?
We expect to find such emergent innovation in artificial intelligence fueled by open-source software.